Puppeteer Web Scraper
The Puppeteer Web Scraper is a powerful tool in AnswerAI that allows you to extract data from webpages. It uses Puppeteer, a Node.js library that controls Chrome or Chromium browsers, to load and scrape web content.
Overview
This feature enables you to load data from single or multiple webpages, with options to crawl relative links or scrape XML sitemaps. It's particularly useful for gathering large amounts of web data for analysis or processing.
Key Benefits
- Easily extract content from complex, JavaScript-rendered websites
- Flexible options for handling multiple pages and sitemaps
- Customizable settings for wait times and CSS selectors
How to Use
-
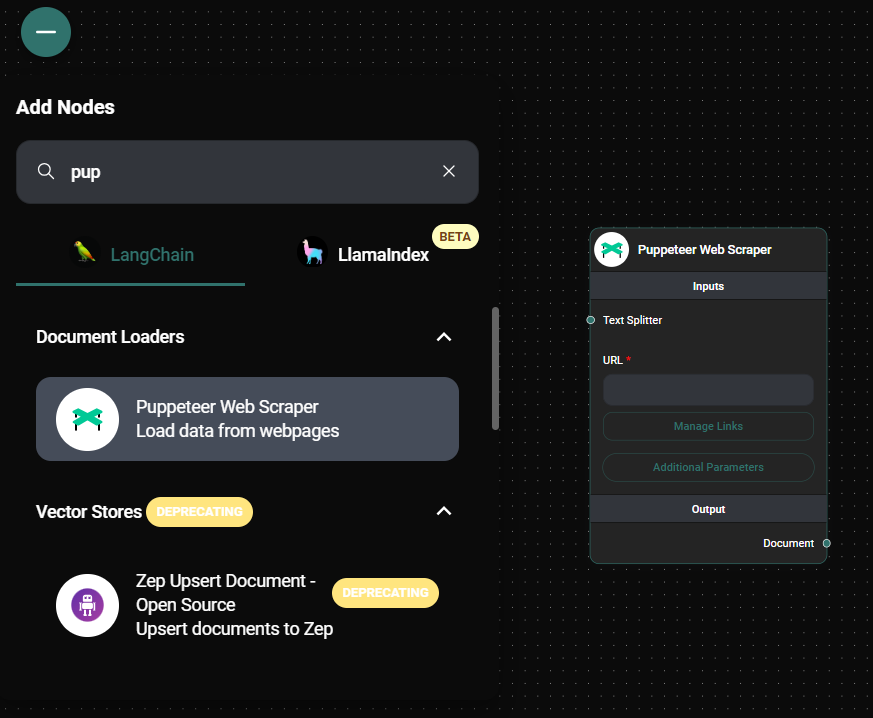
In the AnswerAI interface, locate and select the "Puppeteer Web Scraper" node.
-
Configure the following required settings:
- URL: Enter the webpage URL you want to scrape.
-
(Optional) Connect a Text Splitter node if you want to split the extracted text.
-
(Optional) Configure additional settings:
- Get Relative Links Method: Choose between "Web Crawl" or "Scrape XML Sitemap" to extract multiple pages.
- Get Relative Links Limit: Set the maximum number of links to process (0 for unlimited).
- Wait Until: Select when to consider the page as loaded.
- Wait for selector to load: Specify a CSS selector to wait for before scraping.
- Additional Metadata: Add extra metadata to the extracted documents.
- Omit Metadata Keys: Exclude specific metadata keys from the output.
-
Run the node to start the web scraping process.
Tips and Best Practices
-
Always review and comply with the website's terms of service and policies to ensure ethical and legal use of the data.
-
Use the "Wait Until" option to ensure dynamic content is loaded before scraping.
-
When scraping multiple pages, start with a small limit to test performance before increasing.
-
Utilize the Text Splitter for large documents to create more manageable chunks of text.
-
Add relevant metadata to help organize and identify your scraped content.
Troubleshooting
-
Invalid URL error: Ensure the URL is correctly formatted and includes the protocol (http:// or https://).
-
No data extracted: Check if the website requires JavaScript. Ensure "Wait Until" is set appropriately, or use "Wait for selector to load" for specific elements.
-
Scraping takes too long: Reduce the "Get Relative Links Limit" or optimize your selector choices.
-
Blocked by website: Some websites may block automated scraping. Ensure you're complying with the site's robots.txt and consider adding delays between requests.
Playwright Web Scrapper Node Configuration & Drop UI
Remember to use web scraping responsibly and in compliance with website policies and legal requirements.