Apify Website Content Crawler
The Apify Website Content Crawler is a powerful tool that allows you to extract and load content from websites for use in AnswerAI. This feature is particularly useful for gathering large amounts of web data for analysis, research, or training language models.
Overview
The Apify Website Content Crawler uses advanced web scraping techniques to navigate through websites, clean HTML content, and convert it into a format suitable for processing within AnswerAI. It can crawl multiple pages, follow links, and extract text content efficiently.
Key Benefits
- Easily gather large amounts of web content from specified URLs
- Clean and process HTML to extract relevant text content
- Customize crawling behavior to suit your specific needs
How to Use
-
In the AnswerAI interface, locate and add the "Apify Website Content Crawler" node to your workflow.
-
Configure the node with the following settings:
a. Text Splitter (Optional): Connect a Text Splitter node if you want to split the extracted content into smaller chunks.
b. Start URLs: Enter one or more URLs where the crawler should begin, separated by commas. Example:
https://www.example.com, https://blog.example.comc. Crawler Type: Choose the crawling engine that best suits your needs:
- Headless web browser (Chrome+Playwright)
- Stealthy web browser (Firefox+Playwright)
- Raw HTTP client (Cheerio)
- Raw HTTP client with JavaScript execution (JSDOM) [experimental]
d. Max Crawling Depth: Set the maximum number of links the crawler should follow from the start URL(s).
e. Max Crawl Pages: Specify the maximum number of pages to crawl.
f. Additional Input (Optional): Provide any additional configuration options in JSON format.
g. Additional Metadata (Optional): Add extra metadata to be included with the extracted documents.
h. Omit Metadata Keys (Optional): Specify metadata keys to exclude from the final output.
-
Connect your Apify API credentials:
- If you haven't already, create an Apify account and obtain an API token.
- In AnswerAI, create a new credential for the Apify API and enter your API token.
-
Connect the Apify Website Content Crawler node to other nodes in your workflow as needed.
-
Run your workflow to execute the web crawling and content extraction process.
Tips and Best Practices
-
Start with a small crawl (low Max Crawling Depth and Max Crawl Pages) to test your configuration before scaling up.
-
Use the Stealthy web browser option if you encounter websites that block traditional web scrapers.
-
Respect website terms of service and robots.txt files when crawling.
-
Utilize the Additional Input option to fine-tune crawler behavior for specific websites.
-
Combine the Apify Website Content Crawler with Text Splitters and Vector Stores for efficient document processing and storage.
Troubleshooting
-
If the crawler fails to extract content, try a different Crawler Type or adjust the Additional Input settings.
-
Ensure your Apify API token is correct and has sufficient permissions.
-
If you encounter rate limiting or blocking, reduce crawling speed or use the Stealthy web browser option.
-
For websites with complex JavaScript, use the Headless web browser or JSDOM options to ensure proper content rendering.
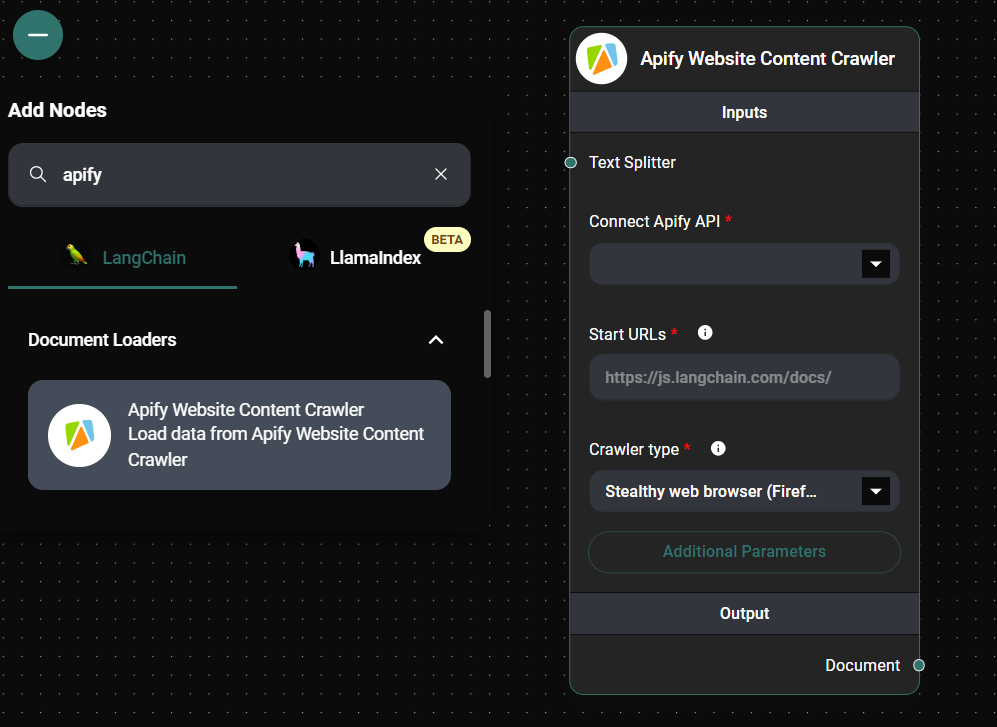
Apify website Content Crawler Node Configuration & Drop UI
By following these instructions, you can effectively use the Apify Website Content Crawler to gather web content for your AnswerAI projects. This powerful tool opens up a world of possibilities for data collection and analysis within your workflows.