GitHub Document Loader
Overview
The GitHub Document Loader is a powerful feature in AnswerAI that allows you to load and process data directly from GitHub repositories. This tool is perfect for users who want to analyze, search, or work with content stored in GitHub, whether it's documentation, code, or other text-based files.
Key Benefits
- Easy access to GitHub repository content without manual downloading
- Flexible options for loading specific branches, files, or directories
- Ability to process both public and private repositories
How to Use
- In the AnswerAI interface, locate and select the "GitHub" option in the Document Loaders category.
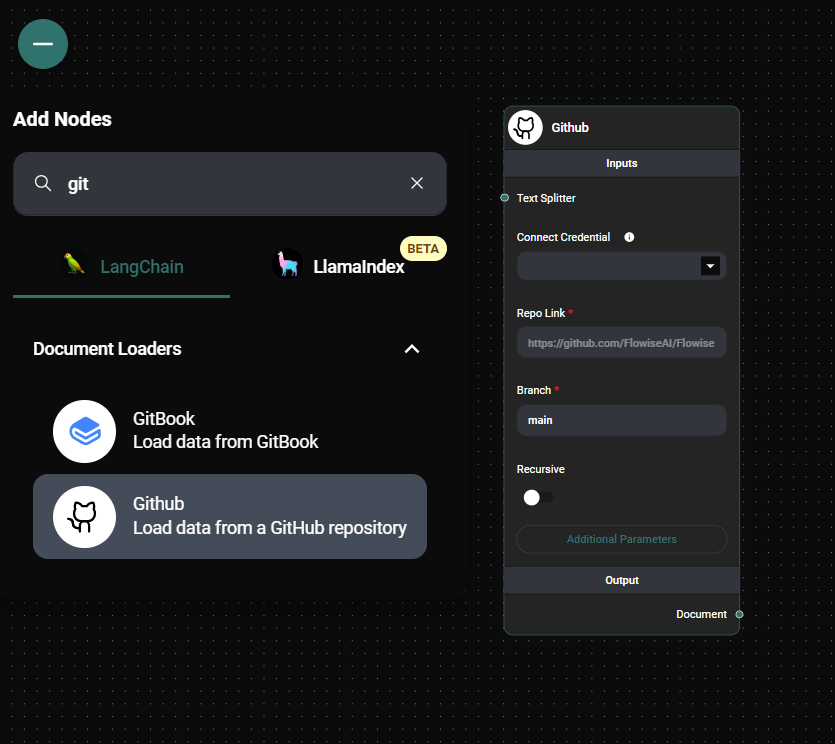
Github Loader Configuration & Drop UI
-
Configure the loader with the following required settings:
- Repo Link: Enter the full URL of the GitHub repository (e.g.,
https://github.com/the-answerai/answers-ai - Branch: Specify the branch you want to load (default is "main")
- Repo Link: Enter the full URL of the GitHub repository (e.g.,
-
(Optional) Customize your loader with additional settings:
- Recursive: Enable this to load files from subdirectories
- Max Concurrency: Set the maximum number of concurrent requests
- Ignore Paths: Specify file patterns to ignore (e.g.,
["*.md"]) - Max Retries: Set the maximum number of retry attempts for failed requests
- Text Splitter: Choose a text splitter to process the loaded documents
- Additional Metadata: Add custom metadata to the extracted documents
- Omit Metadata Keys: Exclude specific metadata keys from the loaded documents
-
If you're accessing a private repository, connect your GitHub API credential:
- Click on "Connect Credential"
- Select or add your GitHub API credentials
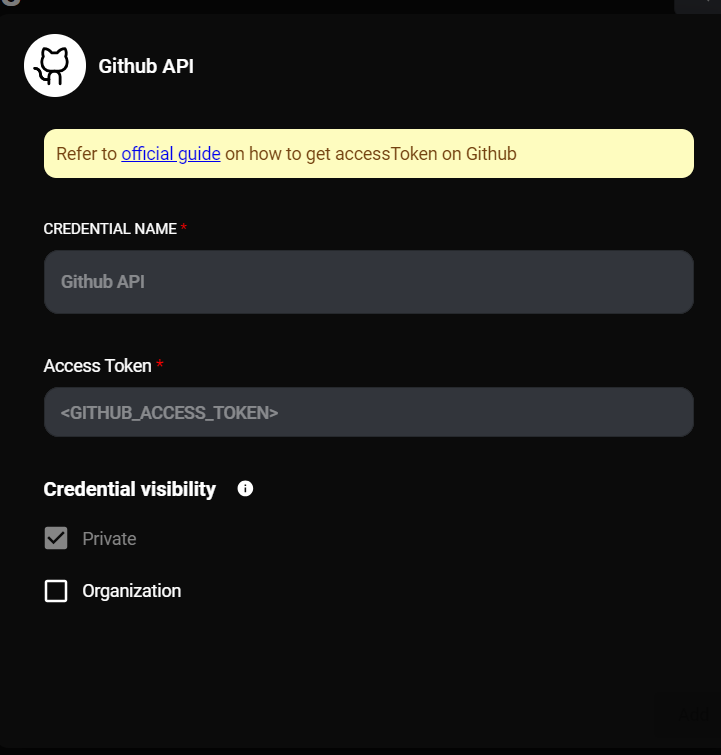
Github API Configuration & Drop UI
- Run the loader to fetch and process the documents from the specified GitHub repository.
Tips and Best Practices
-
Use the "Recursive" option to load entire directory structures, but be cautious with large repositories as it may take longer to process.
-
Leverage the "Ignore Paths" feature to exclude unnecessary files (like images or binaries) that might slow down the loading process.
-
When working with large repositories, adjust the "Max Concurrency" setting to optimize loading speed while respecting GitHub's rate limits.
-
Utilize the "Text Splitter" option to break down large documents into more manageable chunks for further processing or analysis.
-
Take advantage of the "Additional Metadata" feature to add relevant information to your documents, making them easier to categorize or search later.
Troubleshooting
-
If you encounter rate limit errors:
- Reduce the "Max Concurrency" setting
- Increase the "Max Retries" value
- Ensure you're using authenticated requests for higher rate limits
-
For "Repository not found" errors:
- Double-check the repository URL
- Ensure you have the necessary permissions to access the repository
- Verify that your GitHub API credentials are correctly set up for private repositories
-
If certain files are not being loaded:
- Check the "Ignore Paths" setting to ensure you're not accidentally excluding desired files
- Verify that the files are in the specified branch
-
For slow loading times:
- Consider using the "Ignore Paths" feature to exclude large or unnecessary files
- Adjust the "Max Concurrency" setting to find the optimal balance between speed and stability
By following these instructions, you'll be able to effectively use the GitHub Document Loader in AnswerAI to access and process content from GitHub repositories, enhancing your workflow and data analysis capabilities.