Playwright Web Scraper
Overview
The Playwright Web Scraper is a powerful tool in AnswerAI that allows you to load and extract data from web pages. It uses the Playwright library, which automates web browsers for efficient web scraping. This feature is particularly useful for gathering information from websites, performing web research, or collecting data for analysis.
Key Benefits
- Efficiently scrape content from single or multiple web pages
- Customize scraping parameters for precise data extraction
- Integrate with text splitters for advanced document processing
How to Use
Scraping a Single URL
- In the AnswerAI interface, locate and select the "Playwright Web Scraper" node.
- In the "URL" field, enter the web address you want to scrape.
- (Optional) Connect a Text Splitter node if you need to process the scraped content further.
- Run the workflow to initiate the scraping process.
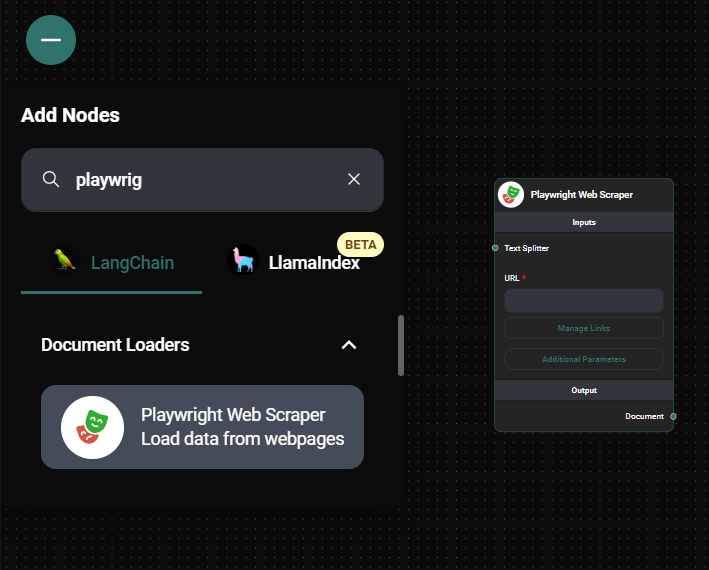
Playwright Web Scrapper Node Configuration & Drop UI
Crawling and Scraping Multiple URLs
To scrape multiple pages, you can use the web crawling feature:
- In the "Get Relative Links Method" dropdown, select either "Web Crawl" or "Scrape XML Sitemap".
- Set the "Get Relative Links Limit" to specify how many pages to crawl (use 0 for unlimited).
- Run the workflow to start the crawling and scraping process.
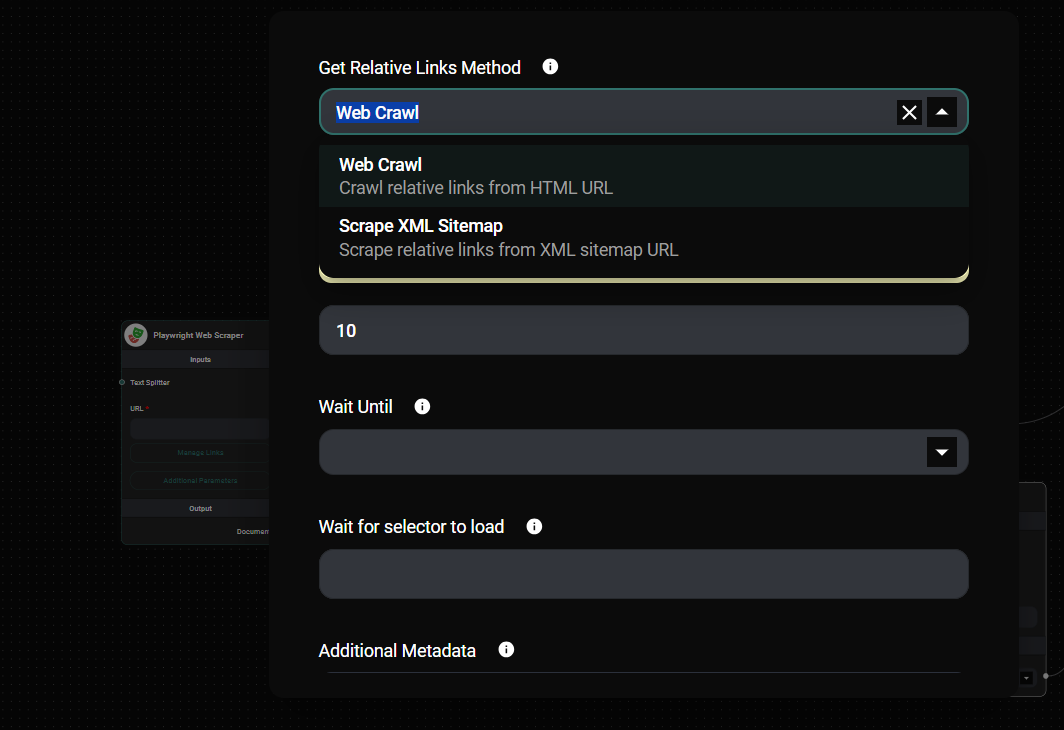
Playwright Web Scrapper Node Configuration & Drop UI
Advanced Options
- Wait Until: Choose when to consider the page loaded (e.g., "Load", "DOM Content Loaded", "Network Idle").
- Wait for selector to load: Specify a CSS selector to wait for before scraping.
- Additional Metadata: Add custom metadata to the extracted documents.
- Omit Metadata Keys: Exclude specific metadata keys from the output.
Tips and Best Practices
- Always respect website terms of service and robots.txt files when scraping.
- Use the "Wait for selector to load" option for dynamic websites that load content asynchronously.
- Implement proper error handling in your workflows to manage potential scraping issues.
- Consider using text splitters to break down large scraped documents into more manageable chunks.
- When crawling multiple pages, start with a small limit and gradually increase to avoid overwhelming the target website.
Troubleshooting
- Error: Invalid URL: Ensure the URL is correctly formatted and includes the protocol (http:// or https://).
- No data scraped: Check if the website requires JavaScript to load content. You may need to adjust the "Wait Until" option.
- Scraping takes too long: For large websites, consider using the "Get Relative Links Limit" to restrict the number of pages scraped.
- Blocked by website: Some websites may block automated scraping. Consider adding delays between requests or using rotating IP addresses.
Output
The Playwright Web Scraper outputs the scraped content as Document objects, which can be further processed or analyzed in your AnswerAI workflow.
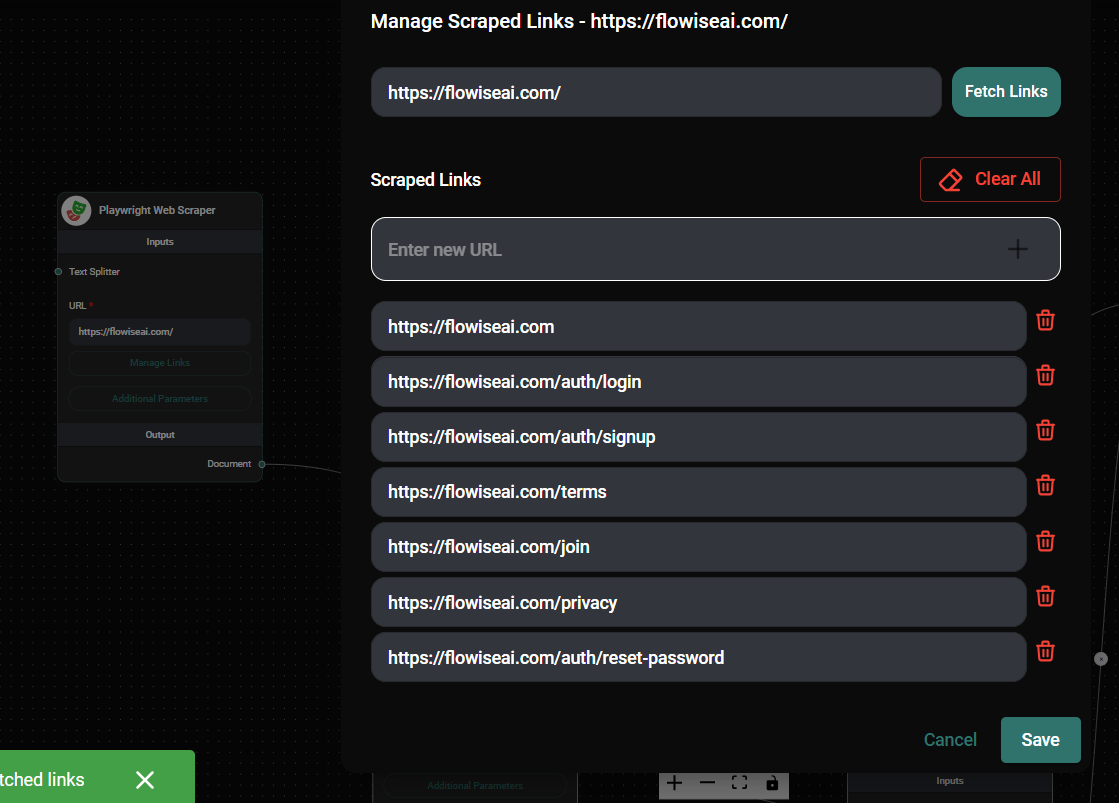
Playwright Web Scrapper Node Configuration & Drop UI
Remember to use web scraping responsibly and in compliance with website policies and legal requirements.