Supabase Vector Store
Overview
The Supabase Vector Store node in AnswerAI allows you to store and retrieve embedded data using Supabase's pgvector extension. This feature enables efficient similarity searches and MMR (Maximal Marginal Relevance) queries on your vector data.
Key Benefits
- Efficient storage and retrieval of high-dimensional vectors
- Seamless integration with Supabase for vector operations
- Support for similarity search and MMR queries
How to Use
- Set up a Supabase project and enable the pgvector extension (see Prerequisites section).
- Add the Supabase Vector Store node to your AnswerAI workflow.
- Connect the required inputs:
- Document: Connect to a Document Loader node (optional)
- Embeddings: Connect to an Embeddings node
- Record Manager: Connect to a Record Manager node (optional)
- Configure the node parameters:
- Supabase Project URL: Enter your Supabase project URL
- Table Name: Specify the name of the table to store vectors (e.g., "documents")
- Query Name: Specify the name of the query function (e.g., "match_documents")
- (Optional) Configure additional parameters:
- Supabase Metadata Filter: JSON object for metadata filtering
- Supabase RPC Filter: Query builder-style filtering
- Top K: Number of top results to fetch (default: 4)
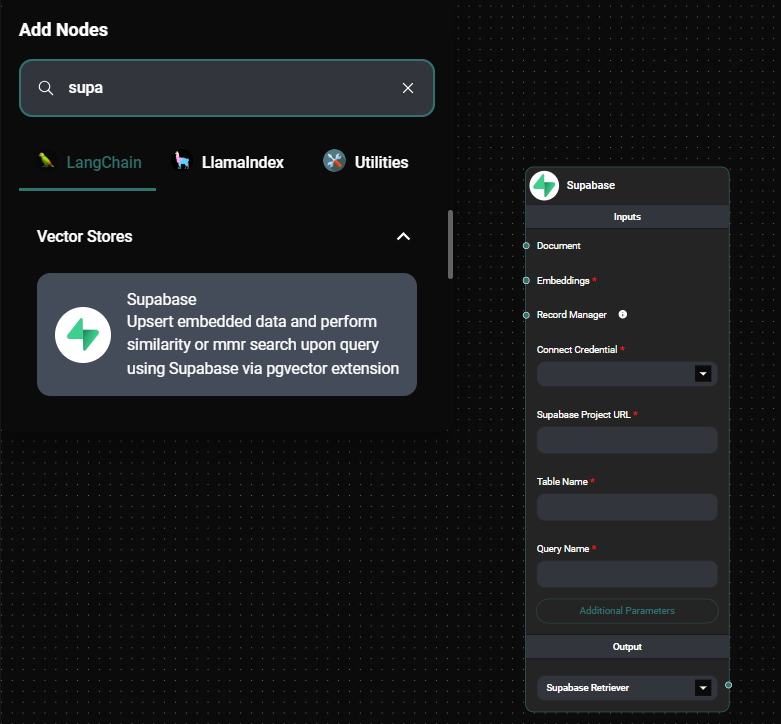
Supabase Vector Store node & Drop UI
Prerequisites
Before using the Supabase Vector Store node, you need to set up a Supabase project and enable the pgvector extension:
- Create a Supabase account and start a new project.
- In your Supabase project, open the SQL Editor.
- Create a new query and run the following SQL to set up the necessary table and function:
-- Enable the pgvector extension
create extension vector;
-- Create a table to store your documents
create table documents (
id bigserial primary key,
content text,
metadata jsonb,
embedding vector(1536)
);
-- Create a function to search for documents
create function match_documents (
query_embedding vector(1536),
match_count int DEFAULT null,
filter jsonb DEFAULT '{}'
) returns table (
id bigint,
content text,
metadata jsonb,
similarity float
)
language plpgsql
as $$
#variable_conflict use_column
begin
return query
select
id,
content,
metadata,
1 - (documents.embedding <=> query_embedding) as similarity
from documents
where metadata @> filter
order by documents.embedding <=> query_embedding
limit match_count;
end;
$$;
Tips and Best Practices
- Use meaningful names for your Supabase table and query function to easily identify them in your project.
- When using a Record Manager, modify the
idcolumn in the SQL setup to usetextinstead ofbigserialto accommodate UUID generation. - Experiment with metadata filtering to refine your search results based on specific criteria.
- Adjust the Top K value to control the number of results returned by the similarity search.
Troubleshooting
- Connection issues: Ensure that your Supabase Project URL and API Key are correct in the node configuration.
- Embedding dimension mismatch: If you encounter errors related to embedding dimensions, make sure the vector size in your SQL setup matches the output of your chosen embedding model (e.g., 1536 for OpenAI embeddings).
- Metadata filtering not working: Double-check the JSON format of your metadata filter and ensure that the metadata keys exist in your stored documents.
If you continue to experience issues, consult the AnswerAI documentation or reach out to support for further assistance.