Pinecone Vector Store
Overview
The Pinecone Vector Store node in AnswerAI allows you to upsert embedded data and perform similarity or MMR (Maximal Marginal Relevance) searches using Pinecone, a leading fully managed hosted vector database. This node enables efficient storage and retrieval of high-dimensional vectors, making it ideal for various AI and machine learning applications.
Key Benefits
- Efficient storage and retrieval of vector embeddings
- Seamless integration with Pinecone's managed vector database
- Support for similarity and MMR search algorithms
How to Use
- Add the Pinecone Vector Store node to your AnswerAI workflow canvas.
- Connect the required input nodes (Document, Embeddings, etc.) to the Pinecone node.
- Configure the node parameters:
- Connect your Pinecone API credential
- Specify the Pinecone Index name
- (Optional) Set additional parameters like namespace and metadata filter
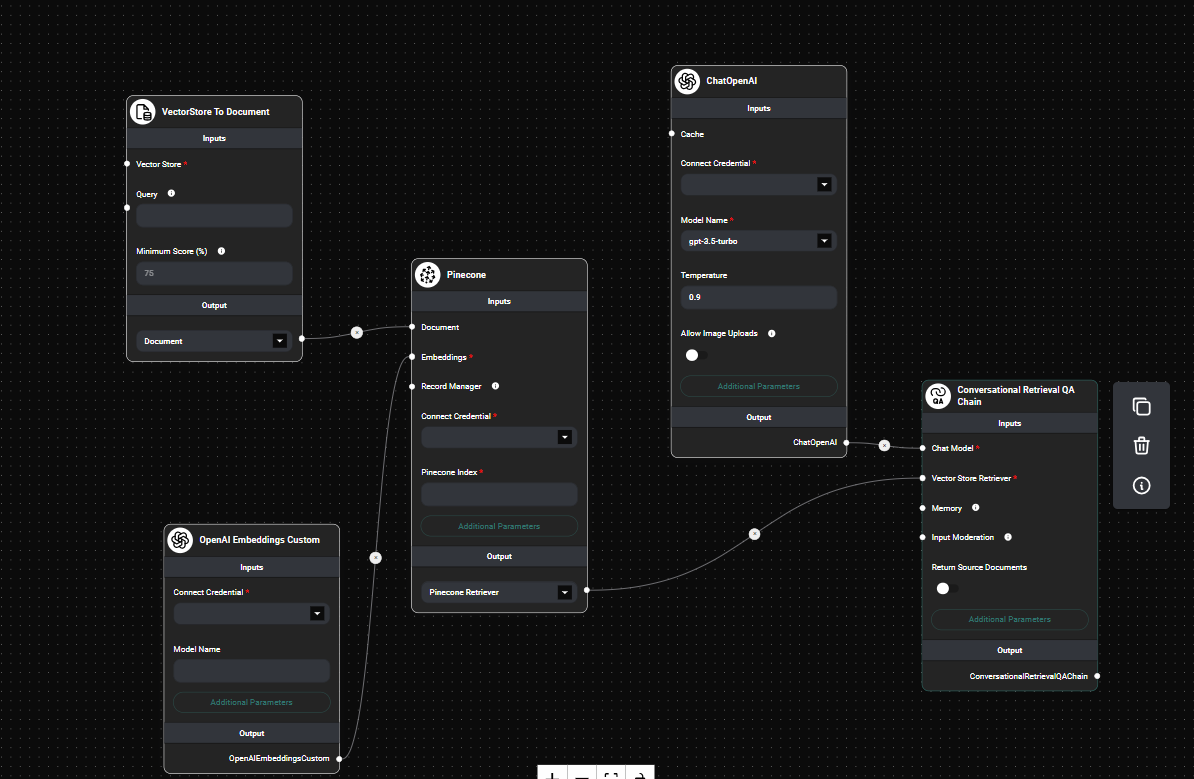
Pinecone Vector Store node configuration & Drop UI
- Connect the output (Pinecone Retriever or Pinecone Vector Store) to subsequent nodes in your workflow.
Node Parameters
- Document: (Optional) Input documents to be stored in the vector database.
- Embeddings: The embedding model used to convert documents into vector representations.
- Record Manager: (Optional) Keeps track of records to prevent duplication.
- Pinecone Index: The name of your Pinecone index.
- Pinecone Namespace: (Optional) A namespace within your Pinecone index.
- Pinecone Metadata Filter: (Optional) JSON object to filter vectors based on metadata.
- Top K: (Optional) Number of top results to fetch (default: 4).
Tips and Best Practices
- Ensure your Pinecone API credential is properly set up in AnswerAI before using this node.
- Use meaningful names for your Pinecone index and namespace to organize your vector data effectively.
- Experiment with different embedding models to find the best performance for your specific use case.
- Utilize the metadata filter to narrow down search results when dealing with large datasets.
Troubleshooting
-
Connection Issues: If you're unable to connect to Pinecone, verify that your API key is correct and that you have the necessary permissions to access the specified index.
-
Indexing Errors: If documents fail to index, check that your embedding model is compatible with the document format and that the documents contain valid content.
-
Search Performance: If search results are not as expected, try adjusting the 'Top K' parameter or refining your metadata filter to improve relevance.
Remember to refer to the Pinecone documentation for more detailed information on index management and best practices for vector search optimization.