Reciprocal Rank Fusion Retriever
Overview
The Reciprocal Rank Fusion (RRF) Retriever is an advanced retrieval method that enhances search results by generating multiple queries and re-ranking the results. This feature improves the relevance and diversity of retrieved documents, especially for complex or ambiguous queries.
Key Benefits
- Improved search accuracy by considering multiple query variations
- Enhanced result diversity through re-ranking of documents
- Better handling of complex or ambiguous user queries
How to Use
-
Add the "Reciprocal Rank Fusion Retriever" node to your AnswerAI workflow canvas.
-
Connect the required inputs:
- Vector Store Retriever: Connect a vector store retriever node.
- Language Model: Connect a language model node (e.g., GPT-3.5, GPT-4).
-
Configure the node parameters:
- Query (optional): Specify a custom query or leave blank to use the user's question.
- Query Count: Set the number of synthetic queries to generate (default is 4).
- Top K: Specify the number of top results to fetch (default is the base retriever's Top K).
- Constant: Set the constant value for the RRF algorithm (default is 60).
-
Connect the output to subsequent nodes in your workflow.
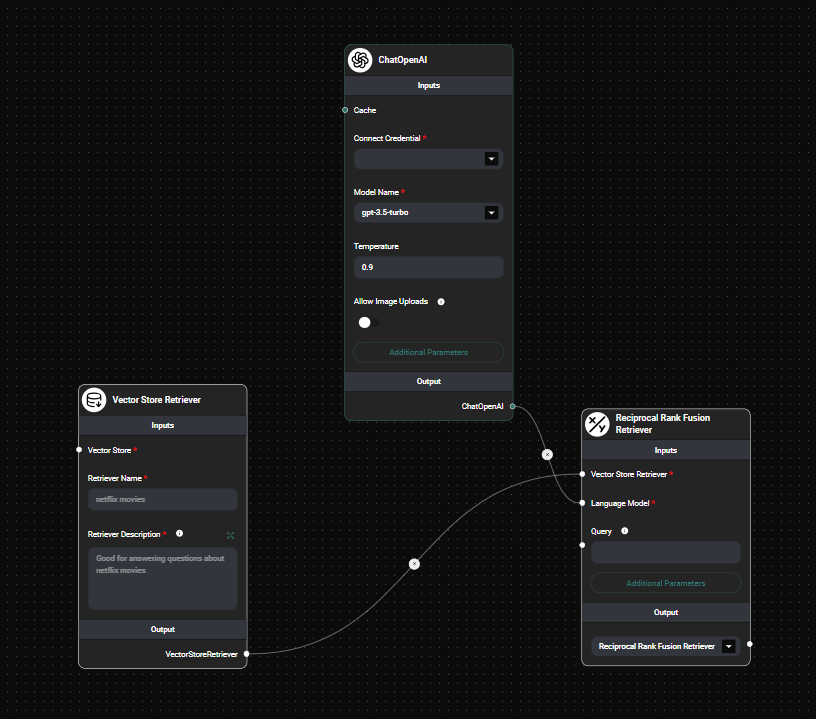
RRF Retreiver Node & Drop UI
Tips and Best Practices
-
Experiment with different Query Count values to find the optimal balance between result quality and processing time.
-
Adjust the Top K value based on your specific use case. A higher value may provide more comprehensive results but might increase processing time.
-
Fine-tune the Constant value to control the balance between high-ranked and lower-ranked items in the results.
-
Use this retriever for queries that might benefit from multiple perspectives or interpretations.
Troubleshooting
-
If results seem less relevant than expected:
- Increase the Query Count to generate more variations of the original query.
- Adjust the Top K value to retrieve more initial results before re-ranking.
-
If processing time is too long:
- Reduce the Query Count or Top K values.
- Ensure your vector store and language model are optimized for performance.
-
If you receive an error about missing inputs:
- Double-check that both the Vector Store Retriever and Language Model inputs are properly connected.