LLM Filter Retriever
Overview
The LLM Filter Retriever is an advanced retrieval node that enhances the document retrieval process by applying contextual compression. It iterates over initially returned documents and extracts only the content that is relevant to the query, providing more focused and accurate results.
Key Benefits
- Improves retrieval accuracy by filtering out irrelevant content
- Reduces noise in retrieved documents, focusing on query-relevant information
- Enhances the quality of input for downstream tasks in your AnswerAI workflow
How to Use
- Add the LLM Filter Retriever node to your AnswerAI canvas.
- Connect a Vector Store Retriever to the "Vector Store Retriever" input.
- Connect a Language Model to the "Language Model" input.
- (Optional) Provide a specific query in the "Query" input field.
- Choose the desired output type: retriever, document, or text.
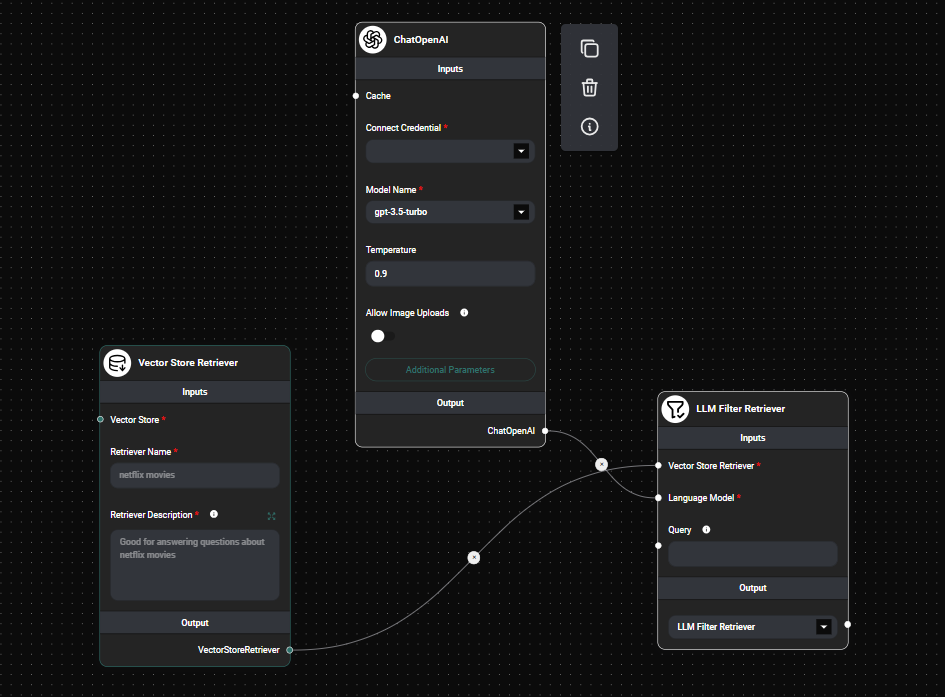
LLM Filter Retreiver Node & Drop UI
Input Parameters
- Vector Store Retriever: Connect a Vector Store Retriever node to provide the base retrieval mechanism.
- Language Model: Connect a Language Model node (e.g., GPT-3, GPT-4) to power the contextual compression.
- Query (optional): Enter a specific query for document retrieval. If not provided, the user's question will be used.
Output Options
- LLM Filter Retriever: Returns the retriever object for use in subsequent nodes.
- Document: Provides an array of document objects containing metadata and filtered page content.
- Text: Returns a concatenated string of the filtered page content from all retrieved documents.
Tips and Best Practices
- Experiment with different Language Models to find the best balance between performance and accuracy.
- Use specific queries when possible to improve the relevance of retrieved content.
- Consider the trade-off between processing time and result quality when using this node in your workflow.
Troubleshooting
-
Error: "There must be a LLM model connected to LLM Filter Retriever"
- Ensure that you have connected a Language Model node to the LLM Filter Retriever.
-
Retrieved content is not relevant to the query
- Try using a more powerful Language Model or refine your Vector Store Retriever's settings.
- Ensure your document collection in the Vector Store is relevant and up-to-date.
-
Slow performance
- The LLM Filter Retriever may increase processing time due to the additional filtering step. Consider using it only when necessary for high-precision tasks.
Remember that the effectiveness of the LLM Filter Retriever depends on the quality of both the Vector Store Retriever and the Language Model used. Experiment with different combinations to achieve the best results for your specific use case.