InMemory Embedding Cache
Overview
The InMemory Embedding Cache feature in AnswerAI allows you to store generated embeddings in local memory. This caching mechanism improves performance by avoiding the need to recompute embeddings for previously processed text, leading to faster response times and reduced computational overhead.
Key Benefits
- Faster processing of repeated or similar text inputs
- Reduced computational resource usage
- Improved overall system efficiency and response time
How to Use
-
Add the InMemory Embedding Cache node to your AnswerAI workflow:
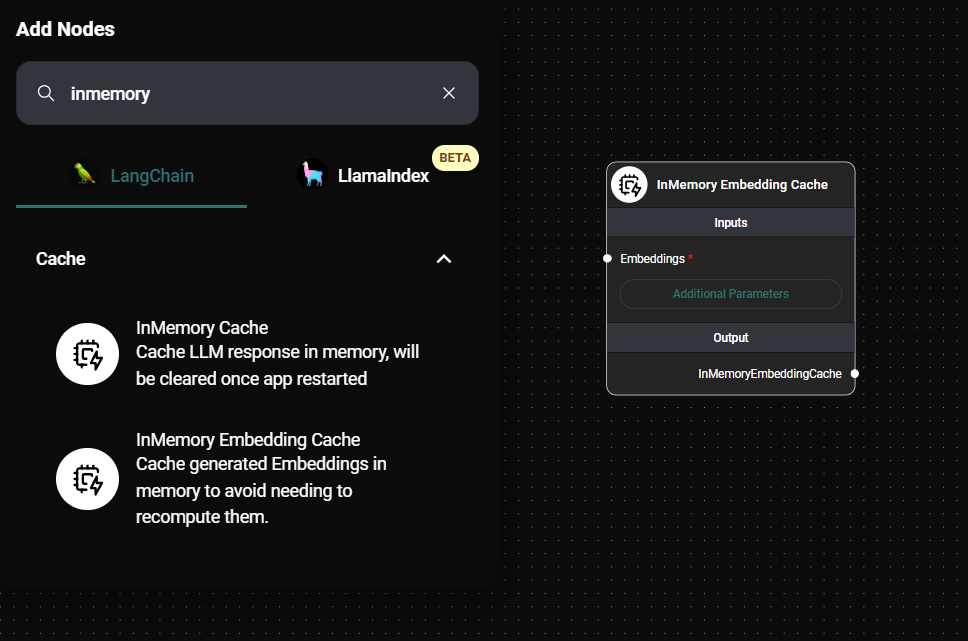
In Memory Embedding Cache & Drop UI
-
Configure the InMemory Embedding Cache node:
- Connect an Embeddings node to the "Embeddings" input.
- (Optional) Specify a "Namespace" for the cache.
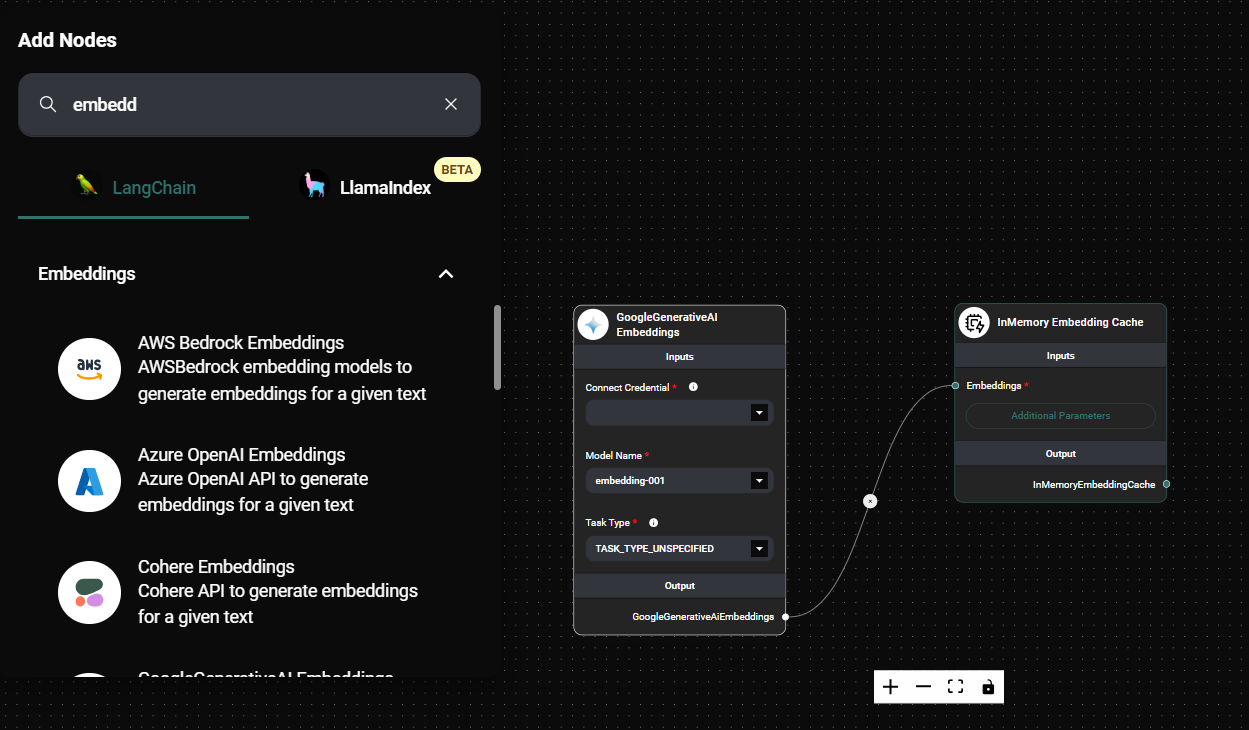
In Memory Embedding Cache Configuration & Drop UI
-
Connect the InMemory Embedding Cache node to other nodes in your workflow that require embeddings:
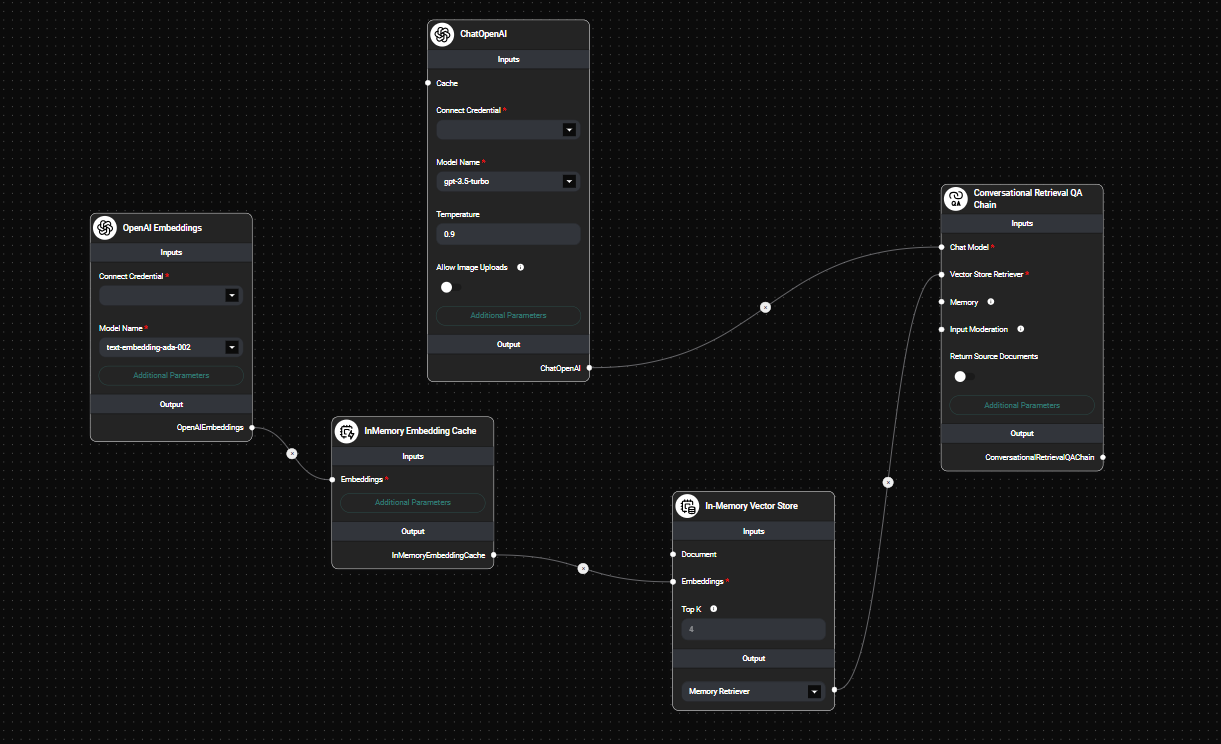
In Memory Embedding Cache In A Workflow & Drop UI
-
Run your workflow:
- The first time a unique text is processed, its embedding will be computed and cached.
- Subsequent identical or similar texts will retrieve the cached embedding, improving performance.
Tips and Best Practices
-
Use caching for repetitive or similar text inputs:
- Ideal for processing documents with recurring phrases or concepts.
- Effective for chatbots or Q&A systems with frequently asked questions.
-
Consider namespace usage:
- Use namespaces to organize embeddings for different purposes or datasets.
- This can help manage cache entries and prevent conflicts between different parts of your application.
-
Monitor memory usage:
- Keep in mind that the cache is stored in memory, which may impact your application's overall memory footprint.
- Consider implementing a cache size limit or periodic clearing mechanism for long-running applications.
-
Combine with persistent storage:
- For long-term caching across application restarts, consider implementing a database-backed embedding cache alongside the in-memory cache.
-
Evaluate cache hit rate:
- Monitor how often cached embeddings are being used versus new computations.
- This can help you optimize your workflow and identify areas where caching is most beneficial.
Troubleshooting
-
Unexpected or inconsistent results:
- Ensure that the Embeddings node connected to the InMemory Embedding Cache is correctly configured.
- Verify that the cache namespace (if used) is consistent across relevant parts of your workflow.
-
High memory usage:
- If your application processes a large volume of unique text, consider implementing a cache eviction strategy or size limit.
- Regularly monitor memory usage and clear the cache if necessary.
-
No performance improvement observed:
- Confirm that your workflow is processing repeated or similar text inputs to benefit from caching.
- Check that the InMemory Embedding Cache node is correctly connected in your workflow.
-
Cache not persisting between sessions:
- Remember that the InMemory Embedding Cache is cleared when the AnswerAI app is restarted.
- For persistent caching across restarts, consider implementing a database-backed caching solution.
Remember that the InMemory Embedding Cache is cleared when the AnswerAI app is restarted. For long-term persistence, consider implementing a database-backed caching solution in addition to or instead of the InMemory Embedding Cache.
By leveraging the InMemory Embedding Cache feature, you can significantly enhance the performance and efficiency of your AnswerAI workflows, especially for tasks involving repetitive text processing or embedding-based operations.