Token Text Splitter
Overview
The Token Text Splitter is a powerful tool in AnswerAI that allows you to split long pieces of text into smaller, more manageable chunks. This splitter works by first converting the text into BPE (Byte Pair Encoding) tokens, then splitting these tokens into chunks, and finally converting the tokens within each chunk back into text.
Key Benefits
- Preserves semantic meaning by splitting text based on tokens rather than arbitrary character counts
- Offers flexibility with various encoding options to suit different types of text
- Allows customization of chunk size and overlap for optimal text processing
How to Use
-
Add the Token Text Splitter node to your AnswerAI workflow canvas.
-
Configure the node with the following parameters:
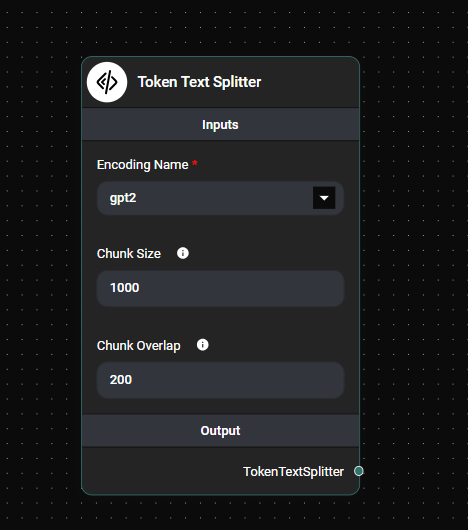
a. Encoding Name:
- Select the appropriate encoding from the dropdown menu (gpt2, r50k_base, p50k_base, p50k_edit, or cl100k_base).
- The default encoding is 'gpt2'.
b. Chunk Size:
- Enter the desired number of characters for each chunk.
- The default value is 1000 characters.
c. Chunk Overlap:
- Specify the number of characters to overlap between chunks.
- The default value is 200 characters.
-
Connect the Token Text Splitter node to your text input source and any subsequent nodes that will process the split text.
Token Text Splitter & Drop UI
Tips and Best Practices
- Choose the appropriate encoding based on your text content and the model you're using in your workflow.
- Experiment with different chunk sizes and overlaps to find the optimal balance between context preservation and processing efficiency.
- Consider the requirements of the nodes that will process the split text when determining your chunk size.
- For most use cases, the default 'gpt2' encoding works well, but specialized tasks might benefit from other encodings.
Troubleshooting
- If your text is not splitting as expected, double-check the chunk size and overlap values to ensure they are appropriate for your content.
- If you encounter performance issues, try reducing the chunk size or using a different encoding that may be more efficient for your specific text.
- Ensure that the encoding you choose is compatible with the models or processes you'll be using later in your workflow.
By using the Token Text Splitter, you can efficiently prepare large volumes of text for further processing in your AnswerAI workflows, ensuring that your AI models receive optimally sized input for the best possible performance.